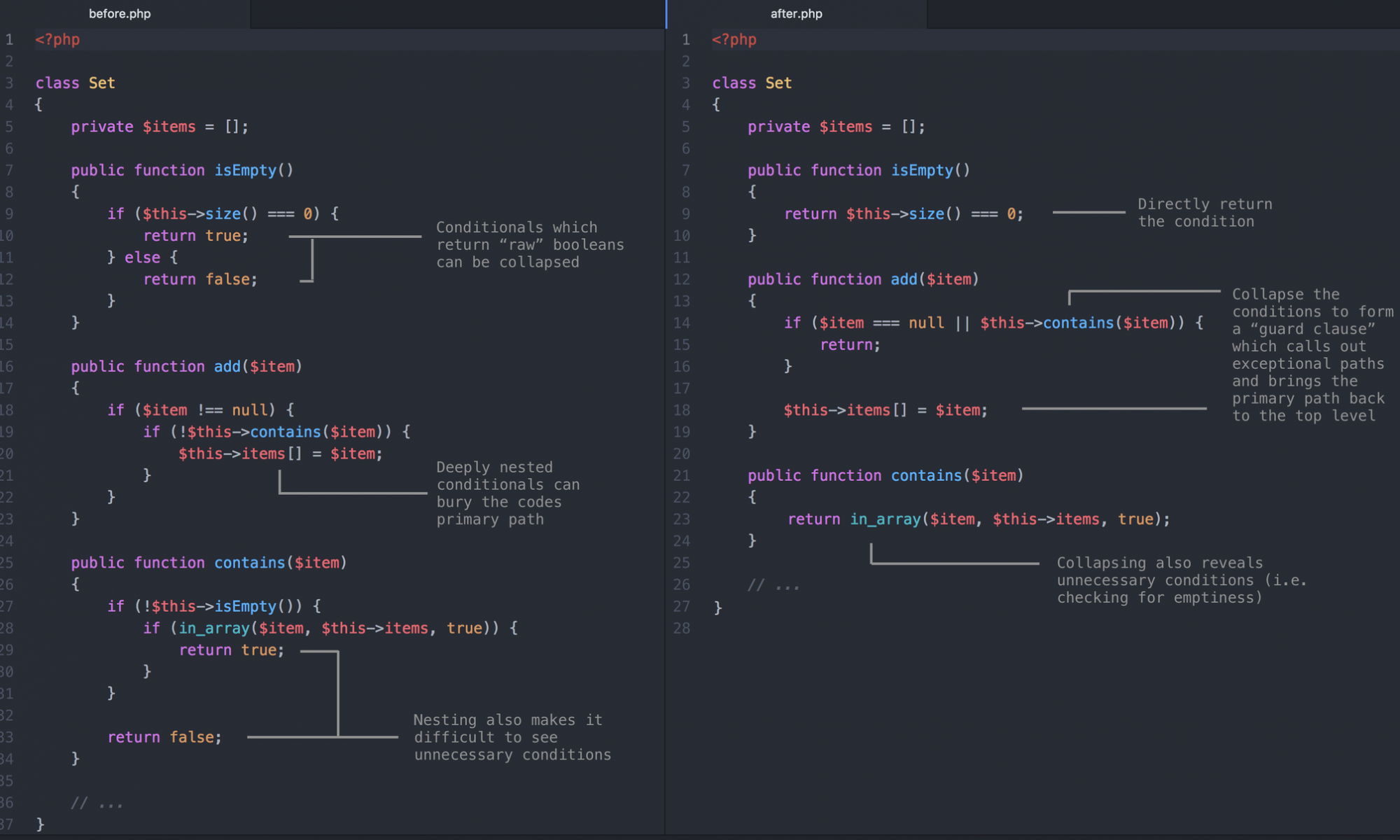
Recientemente me tope con este termino aplicado a Laravel. Al aprender Laravel desde su documentación te da una guía recomendada y funcional de como usarla de una manera exitosa. Sin embargo su eslogan es:
The PHP Framework for Web Artisans
https://laravel.com/
El framework para artesanos Web. Entonces debemos tomar la documentación como una guía y nada más. El resto esta en nuestras manos de artesanos.
Aquí entra el paso extra del service layer. El proceso de un request http en grandes rasgos es así:

Ahora con el service layer sería así
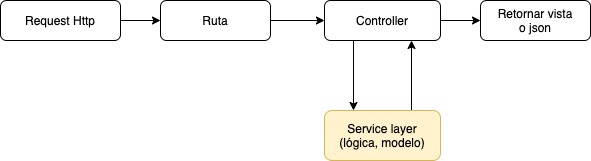
La idea es separar la parte de la lógica del controlador, logrando así tener responsabilidades únicas en cada elemento, el controlador solo tendrá la tarea de llamar a los elementos necesarios y retornar resultados, convirtiéndose es solo un mensajero, manteniendo una arquitectura de software limpia y fácil de mantener.
Service layer es un patrón de diseño que nos permite no repetir código. Permite abstraer la lógica cuando necesitas usar la lógica con diferentes front end. Permite abstraer la lógica de la aplicación a un servicio común.
Ejemplo
Sin service layer
UsersController.php
<?php
namespace App\Http\Controllers;
use App\User;
use Illuminate\Http\Request;
class UsersController extends Controller
{
public function create(Request $request){
$validator = $this->validate($request->all(), [...]);
User::create([
'email' => $request->get('email'),
'name' => $request->get('name'),
'password' => $request->get('password')
]);
return redirect('users')->with('user', $user);
}
}Con service layer
CreateUserService.php
public function make(Request $request)
{
$user = User::create([
'email' => $request->get('email'),
'name' => $request->get('name'),
'password' => $request->get('password')
]);
return $user;
}UsersController.php. Inyecta en el nuevo servicio en el constructor.
public function __construct(CreateUserService $createUserService)
{
$this->CreateUserService = $createUserService;
}
public function store(Request $request)
{
$this->CreateUserService->make($request);
return back()->with(['success' => 'Congratulations!']);
}Así que ahora sabes, puedes crear usuarios desde diferentes lados, por ejemplo un API y un frontend tradicional con blade. O hasta en proyectos con multiples dominios con ui limitadas o diferentes. Ante cualquier cambio solo tendrás que actualizar tu servicio.
Geek de la tecnología, en busca de la mejora y aprendizaje continuo.
Ingeniero en ciencias de la computación, Postgrado en Análisis y predicción de datos